5Euclidean vector spaces
5.1 Vectors in the plane

5.2 Higher dimensions
5.2.1 Dot product, norm and cosine
Suppose that
are vectors in .
-
The dot product between and
is defined by
-
Two vectors are called orthogonal if . We write
this as .
-
The norm of is defined by
-
The distance between the two vectors and is defined by
-
The cosine of the angle between and is defined by
provided that they both are non-zero.
Show that
where .
Use the definition in
(5.3)
to show that
for and .
Let be a nonzero vector and . Use the definition
in
(5.4)
to show that
and that
is a unit vector.
You could perhaps use Exercise
5.4
to do this. Notice also that
is the absolute value for if .
Given two vectors with , find , such
that and are orthogonal, i.e.
For , it is sketched below
that if and are orthogonal, then
and are the sides in a right triangle.
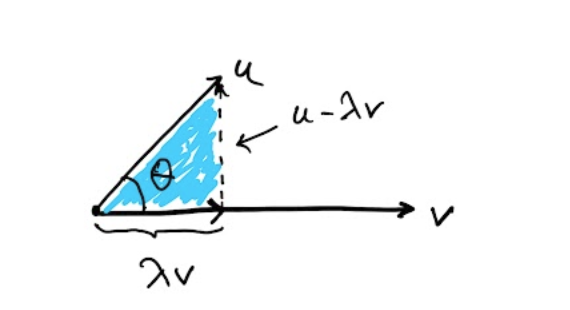 In this case, if is the angle between and , show that
Use this to show that
Finally show that
where and are two angles.
In this case, if is the angle between and , show that
Use this to show that
Finally show that
where and are two angles.
This is an equation, where is unknown!
In the last question, you could use that the vectors
are unit vectors.
Given two vectors , solve the minimization problem
First convince yourself that minimizes
if and only if it minimizes
which happens to be a quadratic polynomial in .
5.3 The unreasonable effectiveness of the dot product
Let denote the distance from to the line through and . What is true about ?
5.3.1 The dist formula from high school
The infamous dist formula from high school says that the distance from the point to the line given by is Where does this magical formula come from? Consider a general line in parametrized form (see Definition 4.10 ) If , then the distance from to is given by the solution to the optimization problem This looks scary, but simply boils down to finding the top of a parabola. The solution is and the point on closest to is .5.3.2 The perceptron algorithm
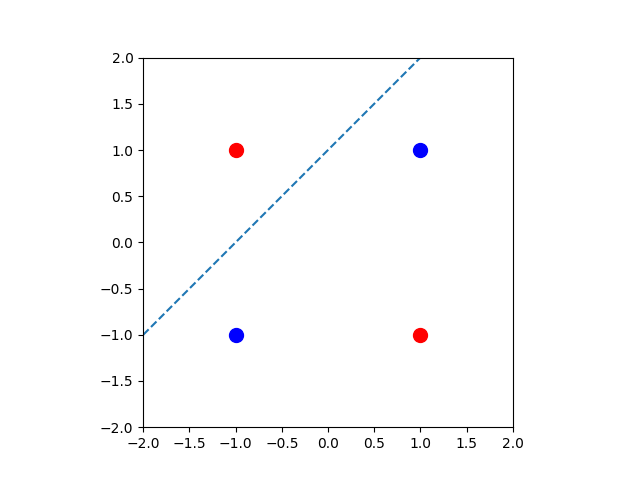
Show that it is imposible to find a line separating the red and blue points above. The red points are
and . The blue points are and .
A ridiculously simple algorithm
Given finitely many vectors , can we find
, such that
for every ?
Come up with a simple example, where this problem is unsolvable i.e., come
up with vectors , where such an does not
exist.
Hint
Try out some simple examples for and .
- Begin by putting .
- If there exists with , then replace by and repeat this step. Otherwise is the desired output vector.
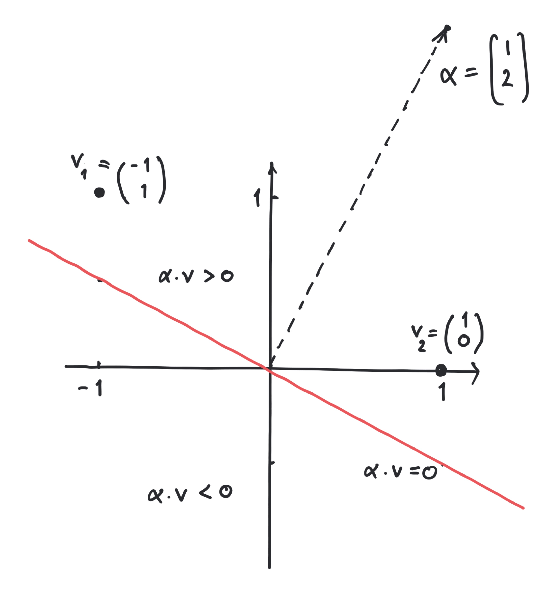
Consider the points
in , where and are labeled by and is labeled by . Then we let
Now we run the simple algorithm above Example
5.11
:
From the last vector we see that determines
a line separating the labeled points.
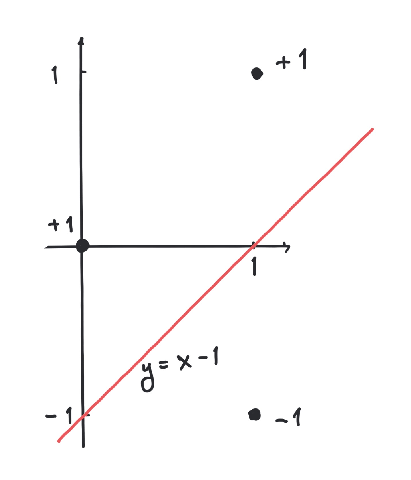
Consider the points
in , where the first point is labeled with and the rest by .
Use the perceptron algorithm to compute a separating hyperplane.
What happens when you run the perceptron algorithm on the above
points, but where the label of
is changed from to ?
5.3.3 Why does the perceptron algorithm work?
We will assume that there exists , such that for every . Therefore and if we put then for every .
Let .
After iterations of the perceptron algorithm, satisfies
where is defined in
(5.9)
.
The algorithm starts with . In the second step we update to
if . For such a we have the following
inequalities
and
If the second step of the algorithm is executed after steps, then we get for the new
that
5.4 Pythagoras and the least squares method
If and , then
This follows from
since .
Suppose we know that is orthogonal to for every . Then
for every
by Proposition
5.15
. So, in the case that
for every we have
for every proving that is an optimal solution to
(5.12)
.
Now we wish to show that is orthogonal to for every if and
only if . This is a computation involving the matrix arithmetic
introduced in Chapter
3
:
for every if and only if . But
so that .
On the other hand, if for every , then for
every : if we could find with , then
for a small number . This follows, since
which is
By picking sufficiently small,
Show that
(5.11)
has no solutions. Compute the best approximate solution to
(5.11)
using Theorem
5.16
.
The classical application of the least squares method is to find
the best line through a given set of points
in the plane .
Usually we cannot find a line matching the points precisely. This corresponds to the fact that
the system of equations
has no solutions.
Working with the least squares solution, we try to compute the best
line in the sense that
is minimized.
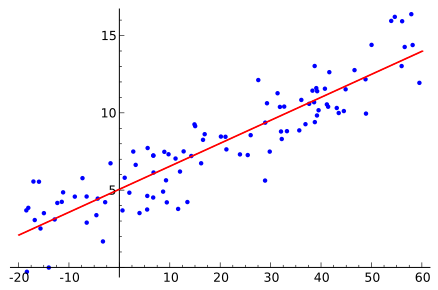
Best fit of line to random points from Wikipedia.
We might as well have asked for the best quadratic polynomial
passing through the points
in .
The same method gives us the system
of linear equations.
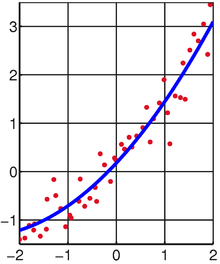
Best fit of quadratic polynomial to random points from Wikipedia.
The method generalizes naturally to finding the best polynomial of degree
through a given set of points.
Find the best line through the points
and and the best quadratic polynomial
through the points
and .
It is important here, that you write down the relevant system
of linear equations according to Theorem
5.16
.
It is however ok to solve the equations
on a computer (or check your best fit on WolframAlpha).
Also, you can get a graphical illustration of your result in the sage window below.
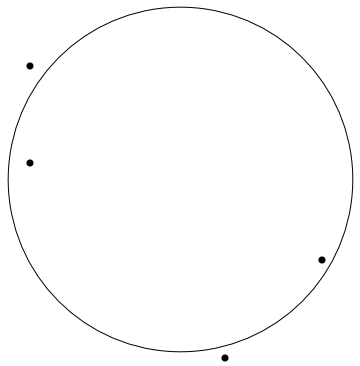
A circle with center and radius is given by the equation
-
Explain how
(5.14)
can be rewritten to the equation
where .
-
Explain how fitting a circle to the points
in the least squares context using
(5.15)
leads to the system
of linear equations.
- Compute the best circle through the points by giving the center coordinates and radius with two decimals. Use the Sage window below to plot your result too see if it matches the drawing.
5.5 The Cauchy-Schwarz inequality
For two vectors ,
We consider the function given by
Then is a quadratic polynomial with . Therefore
its discriminant must be i.e.,
which gives the result.
Why are the two inequalities
a consequence of Theorem
5.23
?
For arbitrary two numbers ,
since
Why is
for arbitary numbers ?
5.5.1 The triangle inequality

For three vectors ,
From the Cauchy-Schwarz inequality (Theorem
5.23
) it follows that
for two vectors .
Since the right hand side of this inequality is , we have
By the definition of , we then get the desired inequality as
Apply the triangly inequality in the form
for to show that
5.5.2 Cosine similarity in machine learning
'a', 'and', 'applicable', 'are', 'fun', 'is', 'mathematics', 'matrices', 'matrix', 'useful'' Each word gets embedded into with a vector associated to its row below
5.6 Special subsets of euclidean spaces


The open ball centered at with radius is defined as
5.6.1 Bounded subsets

A subset is called bounded if there exists , such that
Written out Definition
5.29
says that
for every . Boundedness of is also equivalent to the following two conditions
- There exists , such that for every .
- There exists , such that for and every .
💬
I find the definition below quite hard to understand. It is about bounded subsets.
Please explain it to me patiently, give some examples and test me afterwards.
'''
A subset $S \subseteq \mathbb{R}^n$ is called bounded if there exists $R\in \mathbb{R}$, such that
$$
S \subseteq B(0, R),
$$
where $B(0, R) = \{v\in \mathbb{R}^n \mid d(0, v) < R\}$ and $d$ is the euclidean distance function.
'''
Show precisely that the subset of is not bounded, whereas the subset
is.
Sketch why
is bounded. Now use Fourier-Motzkin elimination to show the same
without sketching.
5.6.2 Open, closed and compact subsets and boundaries and interiors of subsets
Open subsets
An open subset of is a subset consisting of points, that are interior in the following sense:
A subset is called open if for every , there exists , such that
Decide whether each of the subsets given below are open.
Prove that an open ball given by is an open subset.
Suppose that . Define a suitable for and use
Corollary
5.26
to conclude that .
Show that a finite subset of is never open.
If are open subsets, then
are open subsets.
Closed subsets
A subset is called closed if is open.
If are closed subsets, then
are closed subsets.
Decide whether each of the subsets given below are closed.
Open intervals
The following subsets
are open subsets of for every .
Let us prove that is an open subset of .
If , then we let .
Suppose that . If , then and .
If , then and therefore and .
We have proved that is an open subset.
A similiar proof shows that is an open subset. If , then
which is an open subset by the above and Proposition
5.37
.
Closed intervals
The following subsets
are closed subsets of for every .
Compact subsets
A subset is called compact if it is bounded and closed.
The boundary of a subset

The boundary of a subset is defined as
What is the boundary of ? What about ?
The interior of a subset
The interior of a subset is defined by
Let and .
First make a sketch of these two subsets in and respectively. Then
find and .
5.7 Continuous functions
A function , where and is
called continuous at if for every , there exists , such that
for every .
Equivalently,
The function is called continuous if it is continuous at every .
💬
I find the definition below quite challenging to understand. Please explain it to me
patiently with lots of examples. Test me in the end.
'''
A function $f:\rightarrow T$, where $S \subseteq \mathbb{R}^m$ and $T\subseteq \mathbb{R}^n$ is
called \emph{continuous at $v\in S$} if for every $\epsilon > 0$, there exists $\delta > 0$, such that
\begin{equation}
\forall \epsilon > 0\, \exists \delta > 0\, \forall u\in S: d(u, v) < \delta \implies d(f(u), f(v)) < \epsilon.
\end{equation}
'''
The limit of a function at a point
Let in Definition
5.48
. We consider the two functions
where i.e., is the identity function and is a
constant function given by the real number . Both of these
functions are continuous. Let us see why.
For the function ,
(5.17)
reads
This is certainly true if we pick .
For the function ,
(5.17)
reads
Here can be picked arbitrary, since is always true.
5.7.1 An elegant way of characterizing a continuous function
Let be a function. Then is continuous if and only if
is open in for every open subset .
Let be an open subset.
Assume first that is continuous.
We wish to prove that
is open. Pick and so that
. Now use the continuity of to pick
so that
(5.17)
is satisfied i.e.,
Since ,
(5.19)
says that
showing that is an open subset.
Now suppose that is open whenever is open.
For and we put .
Since is an open subset, is open and .
So we may find so that .
But this is exactly the statement that
showing that is continuous.
If is a closed subset and
a continuous function, then the preimage
is a closed subset of .
If is closed, then is open. Therefore
is open by Proposition
5.50
. This implies that is closed.
Let us assume for now that given by is
continuous (see Exercise
5.58
). Then Proposition
5.51
shows that the subset
of is closed, since is a closed subset
of by Proposition
5.42
.
Show formally that the subset
is an open subset of .
5.7.2 Working with continuous functions
The projection functions defined in Definition
1.99
are continuous. In general a function
is continuous if and only if
is continuous for every , where and
.
Lemma
5.54
shows for example that the functions and
are continuous functions from to .
Consider the vector function given by
as an example. To prove that is continuous, Lemma
5.54
tells us that it
is enough to prove that its coordinate functions
are continuous.
Suppose that and are continuous
functions, where and . Then
the composition
is continuous.
Let be functions defined on a subset . If
and are continuous, then the functions
are continuous functions, where (the last function is
defined only if ).
This result is a consequence of the definition of continuity and Proposition
5.56
.
Show in detail that the function given by
is continuous by using Proposition
5.57
combined with
Lemma
5.54
.
Verify the claim in Remark
5.59
.
More advanced (transcendental) functions like and also turn out to be continuous.
We will return to this in the next chapter, where differentiable functions are defined.
Show from scratch (without using Remark
5.59
) that
is a continuous function , where and and
Use Proposition
5.42
and Proposition
5.51
to show that
is a closed subset of .
Hint
Does
exist? What about
Write
where is a suitable (closed) interval.
5.8 Important and special results for continuous functions

Let be a continuous function, where . If
and , then there exists with , such
that .
Use the methods of Example
1.38
to show that
there is no with , where .
Let
be a polynomial of odd degree, i.e. is odd and . Then has a root,
i.e. there exists , such that .
We will assume that (if not, just multiply by ). Consider written as
By choosing negative with extremely big, we have ,
since is negative and
as is positive. Notice here that the terms
are extremely small, when is extremely big.
Similarly by choosing
positive and tremendously big, we have .
By Theorem
5.63
, there exists with with
.
Let be a compact subset of and
a continuous function. Then there exists , such that
for every .
Give two examples, where Theorem
5.66
fails for if we relax
the conditions on .
One, where is open and another one where is not bounded.